Video, How Do Your Tokens Merge?
University of Bristol
eLVM@CVPR 2025

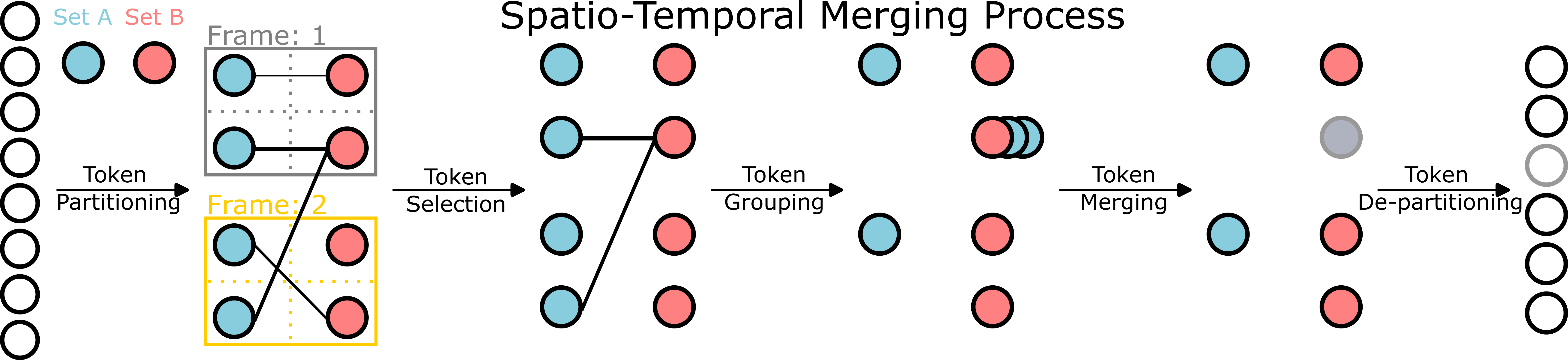
Abstract
Video transformer models require huge amounts of compute resources due to the spatio-temporal scaling of the input. Tackling this, recent methods have proposed to drop or merge tokens for image models, whether randomly or via learned methods. Merging tokens has many benefits: it can be plugged into any vision transformer, does not require model re-training, and it propagates information that would otherwise be dropped through the model. Before now, video token merging has not been evaluated on temporally complex datasets for video understanding. In this work, we explore training-free token merging for video to provide comprehensive experiments and find best practices across four video transformers on three datasets that exhibit coarse and fine-grained action recognition. Our results showcase the benefits of video token merging with a speedup of around 2.5X while maintaining accuracy (avg. -0.55% for ViViT).
Links
Acknowledgments
Research supported by EPSRC Doctoral Training Partnerships (DTP). The authors would like to thank Siddhant Bansal, Prajwal Gatti and Toby Perrett for their comments on the paper. The authors acknowledge the use of resources provided by the Isambard-AI National AI Research Resource (AIRR). Isambard-AI is operated by the University of Bristol and is funded by the UK Government’s Department for Science, Innovation and Technology (DSIT) via UK Research and Innovation; and the Science and Technology Facilities Council [ST/AIRR/I-A-I/1023].
Bibtex
@inproceedings{pollard2025video,
author = {Pollard, Sam and Wray, Michael},
title = {Video, How Do Your Tokens Merge?},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops},
month = {June},
year = {2025},
pages = {3347-3356}
}