A Video Is Not Worth a Thousand Words
University of Bristol
arXiv

Video
Abstract
As we become increasingly dependent on vision language models (VLMs) to answer questions about the world around us, there is a significant amount of research devoted to increasing both the difficulty of video question answering (VQA) datasets, and the context lengths of the models that they evaluate. The reliance on large language models as backbones has lead to concerns about potential text dominance, and the exploration of interactions between modalities is underdeveloped. How do we measure whether we’re heading in the right direction, with the complexity that multi-modal models introduce? We propose a joint method of computing both feature attributions and modality scores based on Shapley values, where both the features and modalities are arbitrarily definable. Using these metrics, we compare 6 VLM models of varying context lengths on 4 representative datasets, focusing on multiple-choice VQA. In particular, we consider video frames and whole textual elements as equal features in the hierarchy, and the multiple-choice VQA task as an interaction between three modalities: video, question and answer. Our results demonstrate a dependence on text and show that the multiple-choice VQA task devolves into a model’s ability to ignore distractors.
Method

Given an input VQA-tuple, we want to know how much each feature contributes towards the model output. We calculate these contributions using Shapley values (which are positive/negative real numbers), resulting in output much like the above animation. Then we take the absolute value (we primarily care about magnitude instead of direction), and either sum them, or average them for each modality. These modality values then form ratios that we call modality contributions (from the contribution of the entire modality) and a per-feature contributions (from the average contribution of each feature). Here our input modalities are video, question and answer.
Results
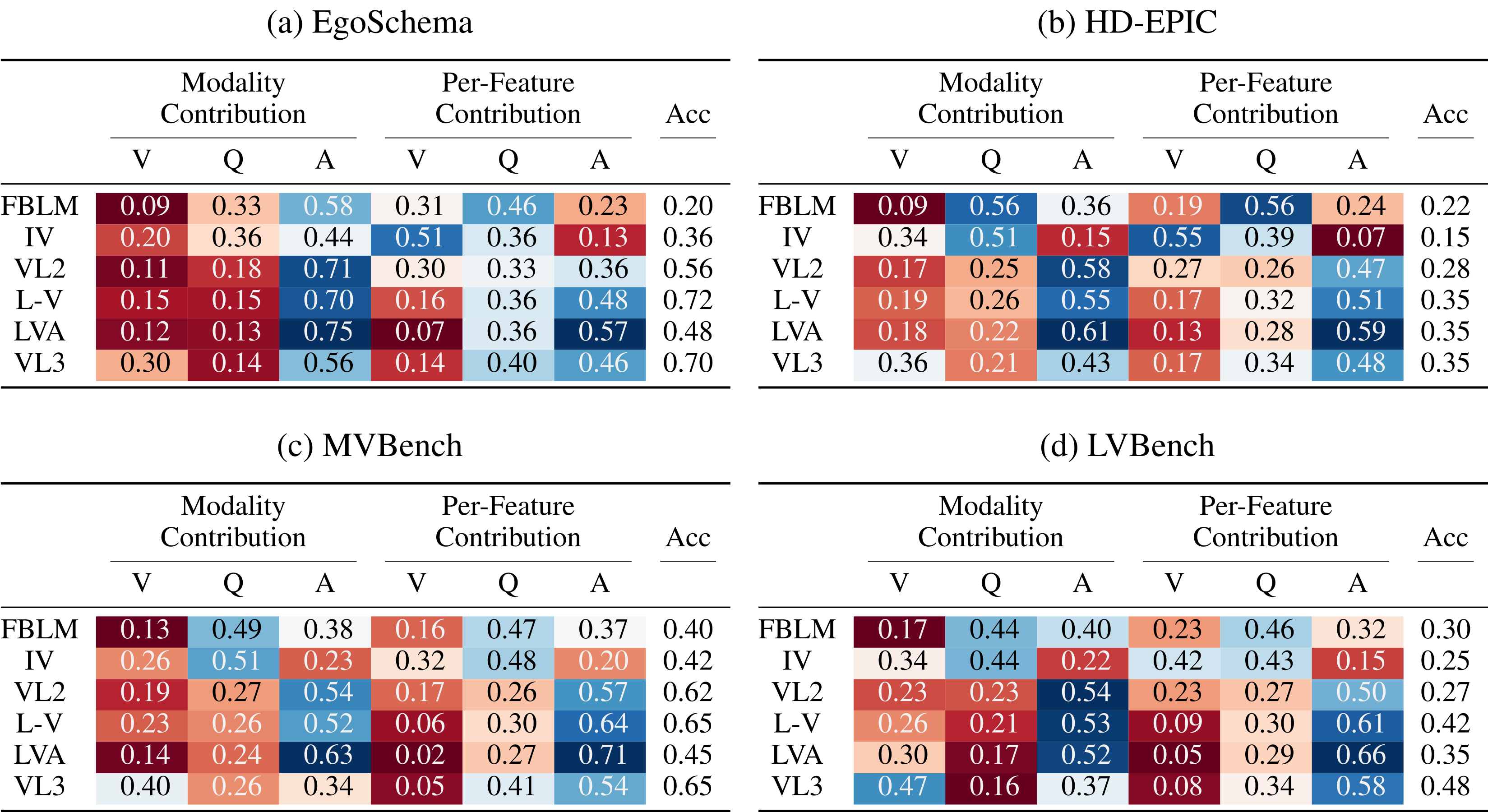
In this table we show our metrics for a range of model and dataset combinations. Red cells are closer to minimum contribution and blue cells are closer to maximum contribution. We see that generally video has low modality contribution, and even the stronger models show extremely low per-frame contributions. Furthermore, question features are consistently less important than answer features. Does this really make sense?
Analysis

Which of these two frames do you think is more important for answering the given question? It’s obviously the one on the right. However, the Shapley values indicate that the one on the left actually contributes more. Just take a look at the teaser figure at the top of the page (compare frame 6 to frame 15). Feature contributions often don’t correlate with common sense, even in extremely simple scenarios.
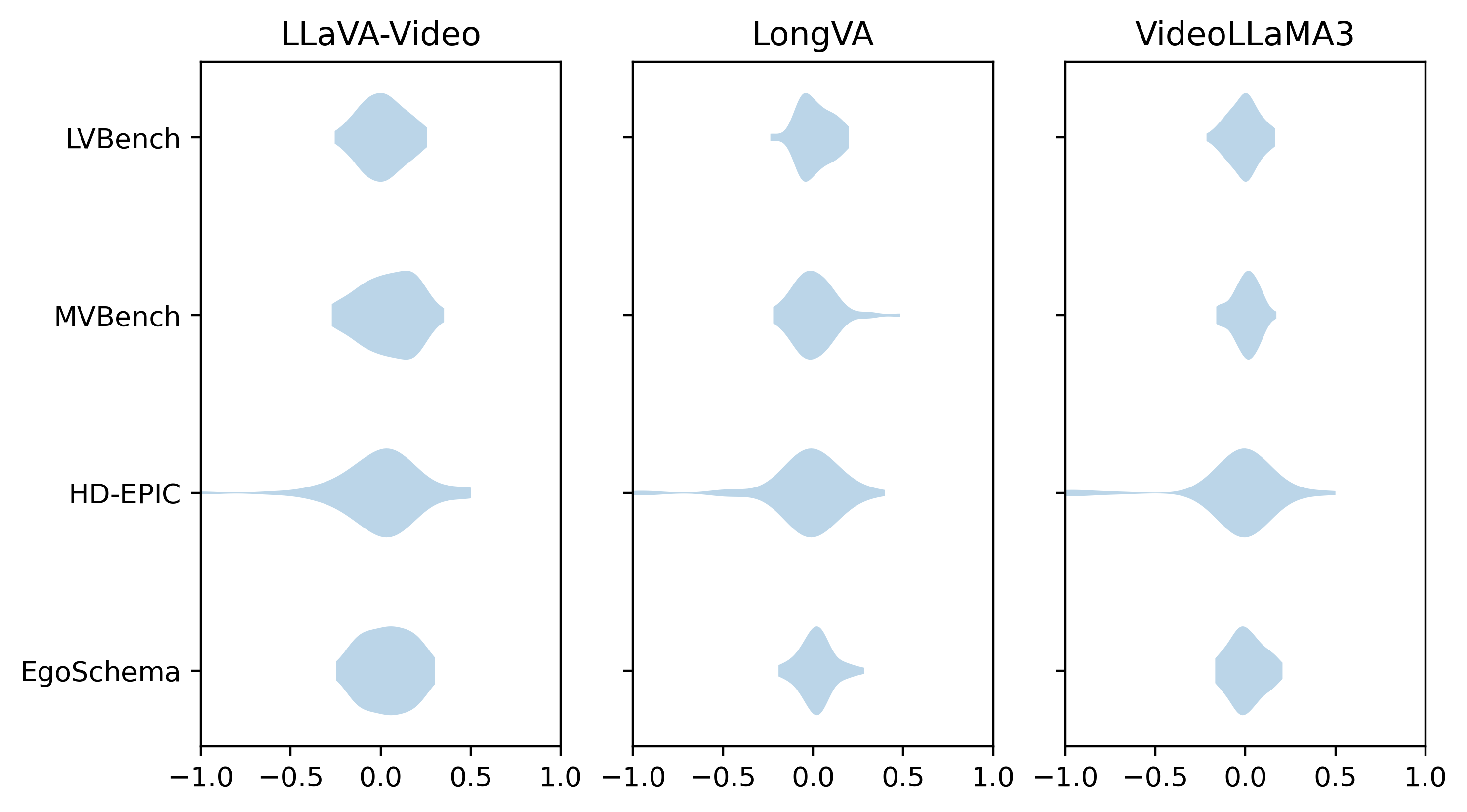
In fact, if we get Gemini to rank the frames in order of importance to answer these questions, we can then directly compare them to the rankings we obtain by sorting the frames by the magnitude of their Shapley values. The above violins plot the Spearman’s correlation between these rankings. They are essentially uncorrelated!
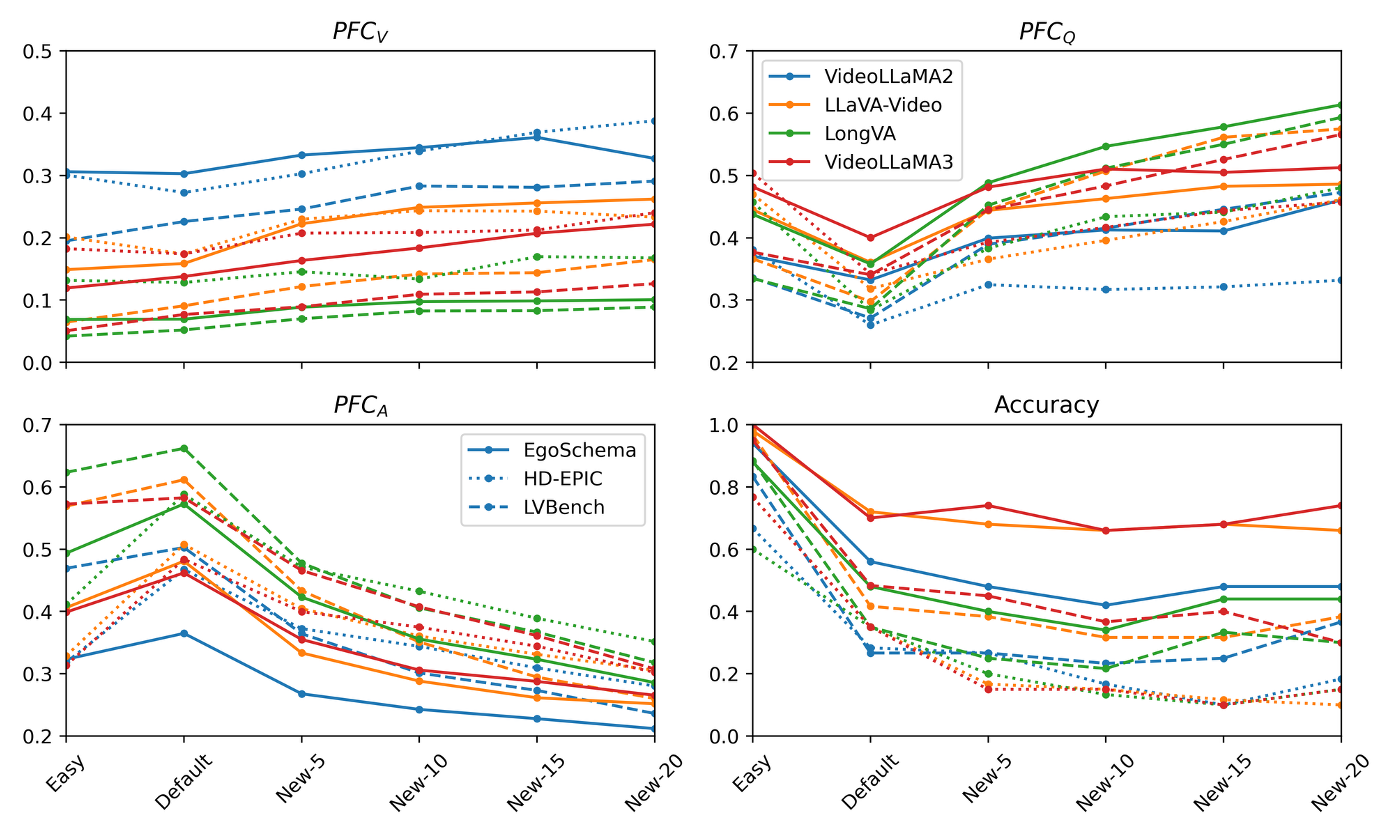
So what’s the path forward? Current multiple choice VQA is clearly lacking when it comes to truly benchmarking the video understanding of these models. Dataset design is difficult, and so is generating good negatives, so it’s extremely rare to see more than 4-5 answer options. We tried injecting new trivial options into VQA-tuples, far beyond this limit. Above we can see that the video and question contributions increase, while answer contributions decrease, with the benchmark also becoming more challenging.
Conclusion
-
Video is necessary for getting the best performance (these models/datasets are not image blind), but information is much denser in the text modality.
-
In principle this might be fine if keyframes are well attended to, but frame attributions often enough don’t make sense.
-
We can add trivial negatives to increase the contribution of video and question modalities (while making the original task no more different for humans).
-
For various reasons, multiple choice VQA is limited in evaluating the understanding of VLMs.
Links
Acknowledgments
Research supported by EPSRC Doctoral Training Partnerships (DTP). The authors would like to thank Rhodri Guerrier and Kranti Parida for their comments on the paper. The authors acknowledge the use of resources provided by the Isambard-AI National AI Research Resource (AIRR). Isambard-AI is operated by the University of Bristol and is funded by the UK Government’s Department for Science, Innovation and Technology (DSIT) via UK Research and Innovation; and the Science and Technology Facilities Council [ST/AIRR/I-A-I/1023].
Bibtex
@article{DBLP:journals/corr/abs-2510.23253,
author = {Sam Pollard and
Michael Wray},
title = {A Video Is Not Worth a Thousand Words},
journal = {CoRR},
volume = {abs/2510.23253},
year = {2025}
}